We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
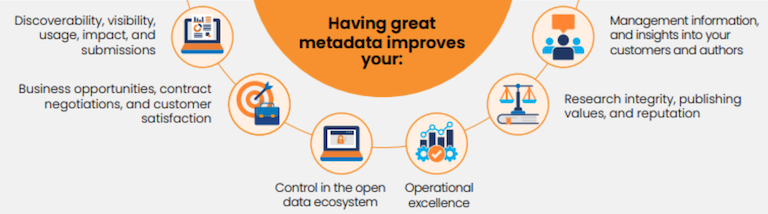
Metadata is communication; it can tell a story about research and paint a picture for others to respond to and learn from, across the world and throughout the forthcoming generations. Metadata can feel technical with words like ‘infrastructure’ and ‘schema’, and sometimes, like tech in general, it comes with hyperbole. But metadata really is part art (storytelling and pictures) and part science (structured models and standards) with both aspects being equally important, and requiring people as well as systems. That necessary combination of human and machine involvement also makes metadata challenging.
Once a year we release all metadata records for content registered with Crossref in a public data file. This year’s version, containing nearly 180 million records, is now available. It includes metadata associated with all Crossref-registered DOIs in JSON-lines format.
Crossref Ambassadors act as local points of contact, meeting editors, librarians, researchers, and institutions to help them navigate Crossref services and understand how strong metadata supports visibility, integrity, and trust in research. They explain how to participate in our rich network of connections between works, people, and institutions, in ways that make sense in their own contexts. And last year, being our 25th anniversary, Ambassadors also massively contributed to our celebrations!
It’s been said that Americans are unusual in tending to ask “Where do you work?” as an initial question upon introduction to a new acquaintance, indicating a perhaps unhealthy preoccupation with work as identity. But in the context of published research, “What is this author’s affiliation?” is a question of global importance that goes beyond just wanting to know the name – and perhaps prestige level – of the place a researcher works.
When collected, used, and analyzed at scale, data about author affiliations can provide intriguing insights about international collaboration trends, signal trust and lack of trust in particular research institutions, generate business intelligence for publishers, help universities track the work their researchers do, help funders demonstrate the impact of their funding, and much more.
In November we partnered with OA Switchboard to organize a roundtable on author affiliation metadata for the Crossref community, service and infrastructure providers, production vendors, data scientists, researchers, and librarians. We aimed to bring together scholarly information professionals with many diverse perspectives; ultimately, participants from more than 40 organizations joined the roundtable to share their experiences and their thoughts.
In focusing on a single type of metadata, we hoped to focus our discussions, as well. Similarly, in October the Barcelona Declaration on Open Research Information organized a roundtable on “Moving Funding Metadata Forward” in which it became clear that “improving the quality and coverage of funding metadata was on the agenda of many organisations and there was a strong interest in collaborating on practical next steps.”
While many of the issues and solutions discussed at both roundtables are similar, in the course of the author affiliation metadata roundtable we identified some unique challenges as well as benefits related to this particular flavor of information. In this blog post, I’ll share these insights.
Insights from presenters
I opened the roundtable with a brief introduction and a working definition of affiliation metadata: names and/or identifiers such as Research Organization Registry (ROR) IDs for organizations where research was conducted or with which authors and contributors are associated, usually officially, as in their place of employment.
Next, to create a shared context for discussion, we heard four presentations on the current state of author affiliation metadata, its importance, and Crossref’s ongoing initiative to enhance it automatically.
Crossref is a foundational data source for bibliographic metadata.
Affiliation metadata is available for only 1 out of 3 journal articles in Crossref for the period 2023-2024.
There is considerable variation in the extent to which Crossref members deposit affiliation metadata.
Downstream sources try to fill gaps using suboptimal approaches, leading to missing, inaccurate, and inconsistent linking of publications to institutions.
Publications lacking affiliation metadata in Crossref are less visible in bibliometric applications, analyses, studies, and tools (such as the open edition of the Leiden Ranking of over 2800 universities).
Next, Yvonne Campfens of OA Switchboard reiterated the desirability of the Crossref community providing complete and accurate author affiliation metadata at the source. Yvonne called upon publishers to “Integrate metadata creation in your systems and workflows before publication and relay it throughout the editorial, production, and publication processes.”
Yvonne pointed out that in the context of managing Open Access agreements, publishers ought to keep in mind that providing good affiliation metadata improves customer satisfaction, since institutions and consortia need to have that information in order to connect research to the correct organization. In closing, Yvonne featured best practices from OA Switchboard’s Data Quality Challenge:
eLife captures affiliations at submissions with “author select,” ensuring that ROR IDs are introduced early and verified before publication, coupled with a quality assurance process during proofing. (See also our piece on Metadata Excellence Award winner eLife.)
EMS Press captures metadata via manuscript extraction as early as at submission, building on globally valid identifiers whenever possible (ROR IDs, DOIs, ORCIDs).
Pensoft Publishers uses AI-assisted metadata extraction with human review and in-house metadata validation.
Beilstein-Institut performs post-acceptance metadata quality assurance through automation and expert review.
The Royal Society embeds metadata in OA payment and agreement workflows.
American Chemical Society (ACS) has a multi-method persistent identifier matching strategy with near-complete coverage.
The American Society for Microbiology (ASM) combines AI-powered submission tools with editorial oversight via expert manual checks. (See also our piece on Metadata Excellence Award winner ASM.)
Rockefeller University Press (RUP) maintains ROR IDs across the full publishing workflow with “author select” at submission through metadata deposits upon publication. (See also the ROR case study on RUP.)
Adam Day of Clear Skies Ltd began his talk by wryly framing the first and second rules of data science as contradictory: “Never fix data: always use sources that produce high-quality data in the first place,” but also “Get good at fixing data, because you will have to.” Adam went on to demonstrate the central role author affiliation metadata plays in research integrity investigations, displaying anonymized data for institutions with a high number of alerts. In conclusion, Adam reiterated the importance of author affiliation metadata to research integrity efforts:
Data analysis is critical to research integrity.
Quality data helps enormously by giving oversight, saving time, and assisting investigations.
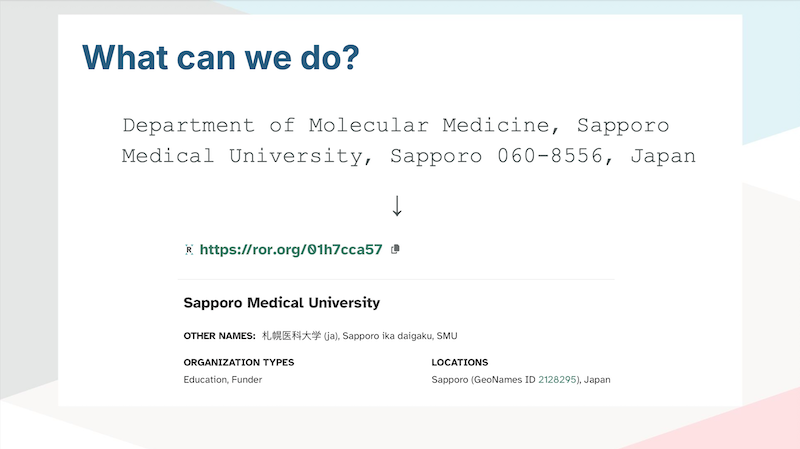
Lastly, our own Director of Technology Dominika Tkaczyk gave an account of our plans to enrich author affiliation metadata by matching organization name text strings to ROR IDs as part of our metadata matching initiative. A strategy for performing such matching has already been developed and tested and an open dataset of results made available. Tests on a set of 3,000 affiliations sampled from our metadata show that the strategy can be expected to match 95 million ROR IDs to organization names with 97.35% precision, an astronomical increase over the less than 1 million ROR IDs deposited in Crossref records to date.
Dominika concluded the presentation portion of the session by reiterating that our planned enrichment of author affiliation metadata
Will use flexible and transparent matching strategies (and open code),
Will welcome community participation in developing new strategies, and
Will be available in the REST API.
Automatic matching of organization names to ROR IDs in author affiliations cannot solve the problem of missing organization names, of course, but it represents a huge leap forward in addressing metadata quality issues.
In the next stage of the event, participants broke into six breakout groups to identify factors contributing to incomplete or inaccurate affiliation metadata. Participants were pre-assigned to groups randomly by role to ensure a variety of perspectives in every discussion.
At least two participants, it should be noted, pointed out that it would be helpful to agree on a definition of “complete” and “accurate” affiliation metadata, which in itself is a challenge, and one we did not address in this roundtable. For instance, practices most recently have trended away from defining a complete author affiliation in open metadata as including an institutional address, although many internal databases might include such information separately.
Even without such definitions, however, all six groups were able to identify several general areas for attention, and one participant provided a particularly helpful categorization of these areas that is largely reused here.
Inherent data complexity
Research organizations have names in different languages, abbreviations, and many other name variants.
Research organizations have frequent name changes, mergers, and rebranding.
Research organizations have different degrees, levels, and complexity of hierarchical granularity, and authors, publishers, and software systems are often misaligned as to which level in an organization’s structure is appropriate to use in a particular instance.
Research organizations often lack official policies on how affiliations should be written, leading to hundreds of variations for a single institution.
Author-related issues
Corresponding authors often submit information for all co-authors, which can lead to inaccuracies.
Many authors have multiple profiles across multiple submission systems, which can introduce errors.
Authors may have “octopus affiliations,” claiming affiliations with many institutions that are difficult to verify.
Authors may fail to update affiliations when changing institutions between manuscript acceptance and publication.
Authors may demonstrate “apathy” when repeatedly filling out submission forms, sometimes providing incomplete, inconsistent, or incorrect information.
On occasion, authors might even provide false or purchased affiliations, which of course is a significant research integrity concern.
Technical barriers
Many manuscript tracking and peer review systems, especially legacy systems, lack structured fields for affiliations or don’t support open organization identifiers like ROR.
Some systems limit authors to a single affiliation, despite many researchers having multiple institutional connections.
Some systems only collect affiliation information for the corresponding author.
Some systems link affiliations to user accounts instead of to publications.
Different systems use competing identifier registries, including proprietary identifier registries, creating interoperability challenges.
Publisher practices
Even when publishers improve current metadata collection practices, historical data correction is resource-intensive and often not prioritized.
Publishers collect affiliation information at submission but don’t ensure that it is maintained throughout all stages of the publication process and deposited in metadata.
Some publishers are unaware of the importance of author affiliation metadata or do not prioritize its improvement.
Some publishers deliberately choose not to deposit affiliation metadata to Crossref, viewing it as value-added information they’ve invested in curating.
Insights into solutions
Naturally, we didn’t rest at identifying challenges: after a break, we gathered in the same groups to brainstorm approaches to improving author affiliation metadata.
Adopt collective approaches
Collective action, where corrections and improvements made by various stakeholders flow back into shared systems, has historically worked for proprietary systems and could be even more powerful with open infrastructure.
Since those who do not provide metadata “upstream” will inevitably have it provided for them “downstream” by multiple separate entities using multifarious methods, provenance metadata indicating who asserted author affiliations and how (whether automatically or with the author’s or editor’s input) would help metadata users assess trust levels.
Engage authors and institutions
Reach out to authors and institutions to educate them on the need for more consistent affiliation reporting, especially in terms of language, name format, and degree of hierarchical granularity.
Demonstrate the benefit to institutions of maintaining accurate records in registries like ROR, including abbreviations and name variants.
Publishers and/or software systems should allow authors to review (though not necessarily edit) affiliation information during the proofing process to verify accuracy. Authors should not, however, need to know, see, or use ROR IDs.
Improve the tech
Publishers would welcome submission systems that incorporate structured fields for author affiliations with well-designed auto-suggestions linked to ROR or other organization identifiers.
Making affiliation data mandatory at submission could significantly improve capture rates, although it would be important to ensure that independent researchers can use these systems as well.
Enable collection of affiliations for all authors, not just the corresponding author.
Increasingly, intelligent matching systems can be implemented to reduce author burden and perhaps also increase accuracy and completeness of metadata.
Better crosswalks between different organization identifier systems would make it vastly easier for publishers to maintain better metadata. Since open registries cannot include proprietary information, proprietary registries should provide their customers with crosswalks to all standard open identifiers.
Encourage publisher best practices
Publishers can use already-available tools to help assess and improve the quality of both new and legacy author affiliation metadata.
Share the benefits of improved author affiliation metadata for internal and external analytics, customer satisfaction, and research integrity.
Identify best practices in collecting and structuring author affiliation metadata.
Understand that the entire research ecosystem would benefit from publishers sharing collected affiliation data with Crossref.
It’s worth mentioning that these solutions are heterogeneous: not all strategies can be implemented by any one actor nor even by any one sector of our profession. Clearly, collaborative action is necessary for substantive change.
Moving forward
The affiliations metadata roundtable represented an important step in addressing affiliation metadata challenges in a productive and collaborative way. If there was a consensus, it was that while perfect completeness and accuracy of author affiliation metadata may not be achievable (or even definable), incremental improvements can substantially enhance the quality and availability of affiliation metadata for the entire scholarly information community.
Here at Crossref, we intend to use the insights from this roundtable to inform our support of the Crossref community, including publishers, service providers, and metadata users. We welcome your comments, questions, and suggestions on this issue! Share your thoughts with Amanda French at alfrench@crossref.org.